Auf einen Blick
- Vier Studierendenteams entwickelten insgesamt zwölf Prototypen in Google ADK, LangChain/LangGraph, OpenAI Agents SDK und n8n – für denselben Use Case.
- Der Meta-Agent berät Bosch-Mitarbeitende bei der Framework-Auswahl aus dem internen Technologie-Portfolio.
- Multi-Agent-Architekturen mit Orchestrator, RAG und LLM-as-a-Judge erwiesen sich als robustester Ansatz.
- Context Engineering und Tool-Enablement werden wichtiger als klassisches Prompt Engineering.
- Framework-Wahl ist keine rein technische Entscheidung – sie hängt vom Ökosystem, Team und Use Case ab.
Wenn Unternehmen heute KI-Agenten einsetzen wollen, stehen sie vor einer paradoxen Situation: Es gibt mehr Tools und Frameworks als je zuvor – Google ADK, LangChain, OpenAI Agents SDK, n8n, CrewAI, Claude Agent SDK, Cognigy – und ständig kommen neue hinzu. Die Auswahl des richtigen Werkzeugs für einen konkreten Use Case bleibt dadurch schwierig, und ein statischer Framework-Vergleich veraltet schnell. Jedes Framework hat eigene Stärken, Limitierungen und Vendor-Abhängigkeiten. Wer die falsche Wahl trifft, verliert nicht nur Zeit, sondern baut technische Schulden auf, die später teuer werden.
Genau hier setzt ein Projekt an, das ich im Wintersemester 2025/26 gemeinsam mit Bosch und Studierenden durchgeführt habe. Die Aufgabe: Einen generischen KI-Beratungsagenten („Advisor Agent“) entwickeln, der Bosch-Mitarbeitenden hilft, aus dem internen Framework-Portfolio das passende Werkzeug für ihren Agenten-Use-Case zu finden – und der so gestaltet ist, dass er sich laufend an neue Tools, Updates und Marktentwicklungen anpassen kann: ein „Agent for Agents".
1. Die Ausgangslage: Warum Bosch einen Meta-Agenten braucht
Bosch betreibt mit „Ask Bosch" eine interne Plattform, über die Mitarbeitende eigene KI-Agenten erstellen können. Dafür steht ein Katalog freigegebener Frameworks bereit – von Low-Code-Plattformen bis zu Pro-Code-Werkzeugen. Die Herausforderung: Nicht jeder Mitarbeitende kann einschätzen, welches Framework für welchen Use Case geeignet ist. Eine Marketing-Managerin hat andere Anforderungen als ein DevOps-Ingenieur, und beide brauchen fundierte Orientierung statt einer generischen Empfehlung.
Das Ziel: Ein übergeordneter Meta-Agent, der Use-Case-Anforderungen analysiert, internes Wissen über bestehende Proof-of-Concepts einbezieht, aktuelle Framework-Dokumentationen recherchiert und seine Empfehlungen laufend an neue Tools, Framework-Updates und Marktentwicklungen anpasst – einschließlich Begründung, Alternativen und Einschränkungen.
2. Die Teams und ihr Ansatz
Vier Studierendenteams haben sich dieser Aufgabe gestellt – mit unterschiedlichen Framework-Kombinationen und Architekturansätzen, aber demselben Ziel.
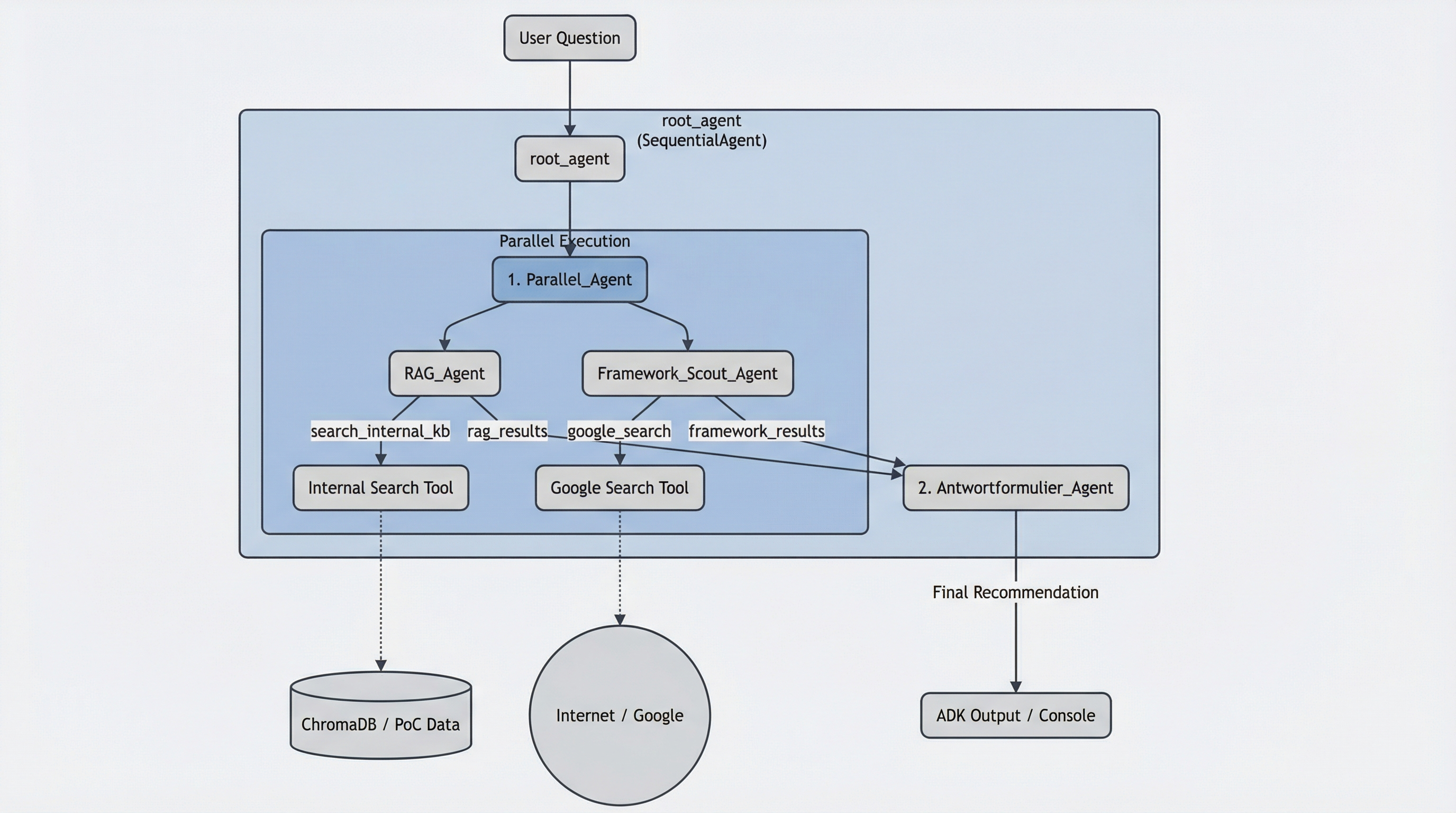
Team 1 – Denisa Casapu, Emilio Vulcano, Jonas Schöpfle und Lukas Plapp – baute drei Prototypen mit LangChain, n8n und Google ADK. Ihr ADK-Prototyp stach hervor: Eine durchdachte Modellwahl (Gemini Flash für Recherche, Gemini Pro für Synthese) und eine Whitelist-Logik, die nicht freigegebene Frameworks automatisch herausfiltert und Alternativen vorschlägt.
Team 2 – Lenny Buck, Sena Imeri und Milena Sengül – legte besonderen Fokus auf unterschiedliche Nutzergruppen. Ihr Dual-UI-Konzept: Erfahrene Nutzende erhalten über ein Formular schnelle, strukturierte Empfehlungen; weniger erfahrene werden im Chat-Dialog schrittweise zur Empfehlung geführt. Ein dedizierter Scoring-Agent bewertet alle Frameworks entlang von Nutzer-Erfahrung, Agententyp und dynamischen Prioritätsgewichtungen.
Team 3 – Amy Klein, Dennis Simutin und Felix Schöck – verfolgte einen besonders systematischen Evaluationsansatz. Auf Basis wissenschaftlicher Literatur entwickelten sie einen Entscheidungsbaum für die Framework-Zuordnung und testeten ihre Prototypen in n8n, LangChain (NextJS Fullstack) und Google ADK (FastAPI + NextJS) iterativ dagegen. Besonders aufschlussreich: Ihr systematischer Vergleich verschiedener Agenten-Architekturen – vom Single Agent über Sequential und Loop Agents bis hin zu Multi-Agent-Systemen.
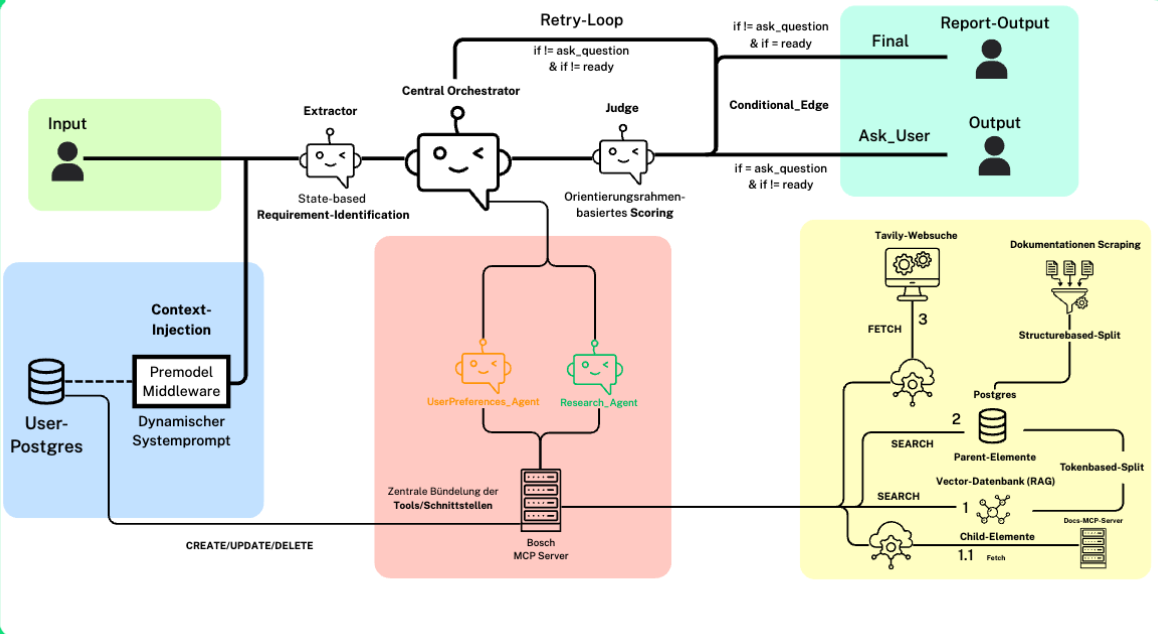
Team 4 – Lili Ertel, Jan Staudinger, Paul Shuhaiber und Andreas Walter – entwickelte Prototypen mit Google ADK, OpenAI Agents SDK und LangChain/LangGraph. Ihr LangGraph-Prototyp setzte auf eine durchdachte Architektur mit Extractor-Node, Central Orchestrator, Judge-Node und Conditional Edges. Die Besonderheit: Ein Parent-Child-RAG-System für kontextreichere Antworten und ein MCP-Server als zentrale Tool-Bündelung.
Von Bosch-Seite begleiteten Philipp Schneider, Sonja Buchholz, Lena Dorsch, Alexandros Smponias und Dr. Timurhan Sungur das Projekt – eine Mischung aus Marketing, IT und KI-Expertise, die das Projekt besonders praxisnah machte.
3. Architektur-Patterns: Was sich bewährt hat
Über alle Teams hinweg kristallisierten sich mehrere Architektur-Entscheidungen heraus, die sich als besonders wirksam erwiesen.
Orchestrator als Projektleiter. Alle Teams setzten auf Separation of Concerns: Ein zentraler Orchestrator-Agent delegiert Aufgaben an spezialisierte Sub-Agenten – Recherche, Nutzerprofil-Analyse, Bewertung. Diese Aufteilung steigert die Antwortqualität messbar, weil jeder Agent einen klar definierten Auftrag hat, statt alles in einem einzigen Prompt lösen zu müssen.
Die Begründung dafür zeigte sich klar in der Praxis: Ein Single-Prompt-Ansatz, der gleichzeitig Use Cases verstehen, Framework-Daten recherchieren, Scores berechnen und Text schreiben soll, erzeugt zu viel Context bei sinkender Qualität. Eine Lösung mit sieben spezialisierten Agenten machte jede Teilaufgabe isoliert testbar und wartbar. Die Progression wurde im Projekt besonders anschaulich sichtbar: Vom simplen Single Agent über Sequential und Loop Agents bis zum vollständigen Multi-Agent-System. Das Fazit: Einfach starten und Komplexität nur dort hinzufügen, wo sie nachweislich bessere Ergebnisse liefert.
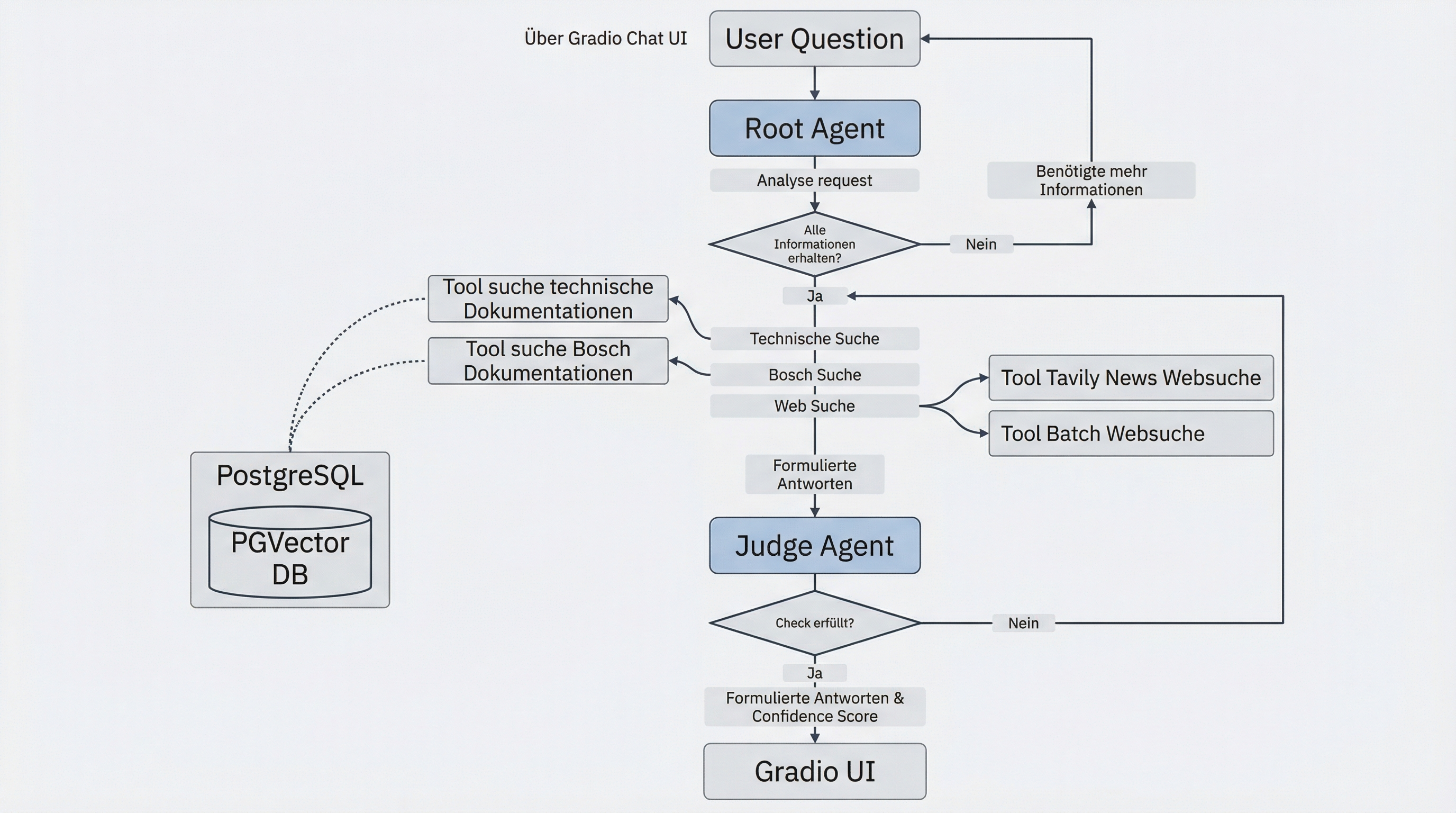
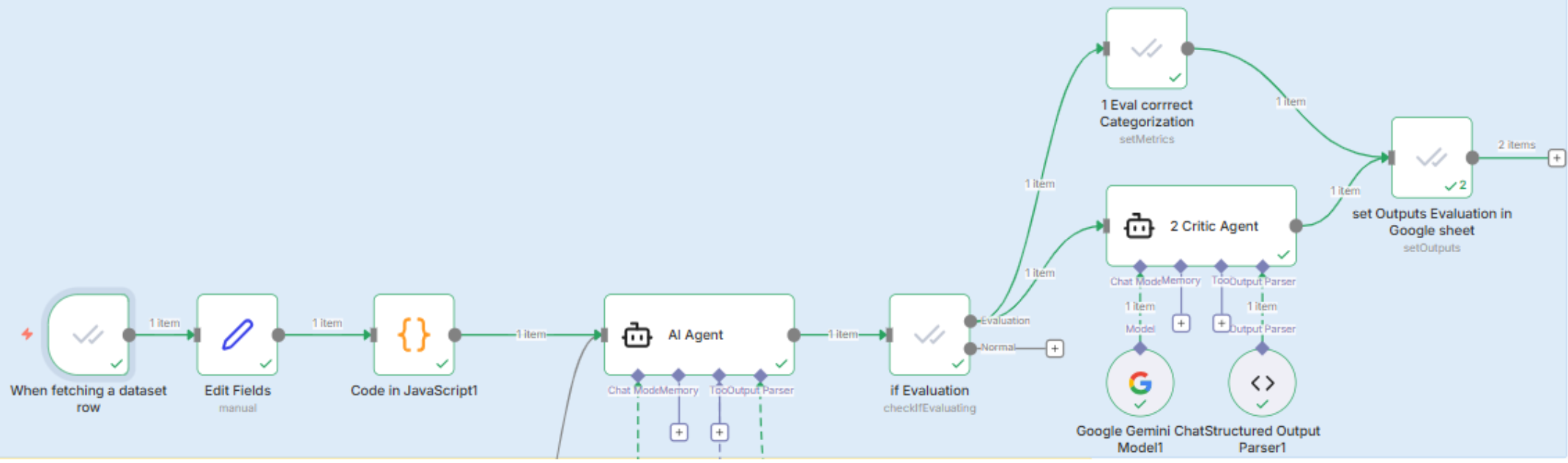
LLM-as-a-Judge für Qualitätssicherung. Alle vier Teams implementierten einen unabhängigen Prüf-Agenten, der Antworten vor der Auslieferung bewertet. Bei einem Score unter dem Schwellenwert wird die Antwort mit Anmerkungen an den Haupt-Agenten zurückgegeben – ein iterativer Feedback-Loop, der Halluzinationen und Lücken korrigiert, bevor Nutzende sie sehen.
Eine wichtige Beobachtung dabei: Der Judge kann nicht „besser" sein als der Recommendation Agent selbst, erhöht aber Token-Verbrauch und Laufzeit deutlich. Der Mehrwert liegt vor allem darin, dass Lücken im Systemprompt schnell sichtbar werden – der Judge fungiert also auch als Entwicklungswerkzeug.
Parent-Child RAG statt Standard-RAG. Ein besonders wirkungsvolles Pattern war ein hierarchisches Retrieval-System: Kleine Child-Chunks ermöglichen präzise Suche, aber die Antwortgenerierung nutzt den vollständigen Parent-Kontext. Standard-RAG liefert bei isolierten Chunks oft unvollständige Informationen – das Parent-Child-Pattern löst dieses Problem elegant.
MCP-Server als Tool-Bündelung. Statt Tools direkt in die Agenten zu verdrahten, bündelten einige Prototypen ihre Schnittstellen über MCP-Server. Getestet wurden unter anderem Context7 MCP, GitHub MCP und Vercel Grep MCP für den Zugriff auf aktuelle Framework-Dokumentationen – mit einem ernüchternden Ergebnis: Die MCP-Tools lieferten trotz längerer Durchlaufzeit keine besseren Ergebnisse als gut kuratierte lokale Dokumentationen.
4. Context Engineering: Der eigentliche Differenzierungsfaktor
Eine der wichtigsten Erkenntnisse des Projekts: Die Qualität der Agenten-Antworten hängt weniger vom gewählten Framework ab als vom Context Engineering – also davon, wie präzise und anwendungsfallspezifisch die Kontextinformationen aufbereitet werden.
Alle Teams investierten erheblichen Aufwand in diesen Bereich. Zum Einsatz kamen unter anderem das COMPASS-Framework (Context, Objective, Mode, People of Interest, Attitude, Style, Specifications) mit JSON als Kommunikationsstandard zwischen Agenten – strukturierte Datenübergabe statt natürlicher Sprache – sowie das CO-STAR-Pattern (Context, Object, Style, Tone, Audience, Response) mit dynamischen System-Prompts, die individuelle Nutzerpräferenzen injizieren.
Ein weiterer Ansatz löste das Context-Problem architektonisch: Ein Anforderungsagent fasst die Einstiegsfragen zu einem strukturierten Anforderungsprofil zusammen und übergibt ein einheitliches Prompt-Paket an alle nachfolgenden Agenten. Andere Prototypen entwickelten den Prompt rein iterativ – die Prompting-Methode entstand aus dem konkreten Testprozess heraus, nicht aus einem theoretischen Framework.
Besonders aufschlussreich: Beim RAG-System erwies sich die Qualität der Eingangsdaten als wichtiger als die Modellwahl. Regex-basierte Metadaten-Extraktion statt reiner Text-Chunks lieferte deutlich bessere Filterung und relevantere Ergebnisse. Ein zusätzlicher Aspekt war ein „Prompting Agent", der Systemprompts automatisch auf Aktualität prüft – ein Ansatz, der zeigt, dass auch die Pflege der Prompts selbst als agentische Aufgabe modelliert werden kann.
5. Framework-Vergleich: Was die Prototypen zeigen
Der direkte Vergleich über vier Frameworks liefert praxisnahe Erkenntnisse:
LangChain/LangGraph bietet maximale Flexibilität und Kontrolle. LangGraph ermöglicht manuelle Ablauflogiken über Graphen und Workflows. Die Stärke: breite Community und Vielfalt an Integrationen. Die Schwäche: hohes Overengineering-Potenzial und ein gewisser Lock-In durch LangSmith auf der Ops-Seite. Für einfache Proof-of-Concepts erzeugt die Graphen-Logik mehr Overhead als nötig – für komplexe Workflows ist sie ein Gewinn.
Google ADK punktet mit vordefinierten Multi-Agent-Patterns und einem strukturierten Enterprise-Pfad für Deployment, Observability und Evaluation. Die integrierte Evaluationsumgebung mit Golden Datasets und Tool-Trajectory-Scoring ist ein echtes Differenzierungsmerkmal. Das ADK Web Interface ermöglicht Live-Nachverfolgung der Agent-Abläufe – ein Vorteil für Debugging und Stakeholder-Kommunikation. Außerhalb des Google-Ökosystems wird es allerdings umständlicher. Die Mehrheit der Teams empfahl daher Google ADK als primären Prototypen für Bosch, weil Bosch bereits im Google-Ökosystem operiert.
OpenAI Agents SDK ermöglicht die schnellste Entwicklung agentischer Anwendungen. Sessions, Guardrails und ein klares Workflow-Modell senken die Einstiegshürde. Allerdings muss die gesamte Orchestrierung eigenständig umgesetzt werden – wer Multi-Agent-Patterns braucht, implementiert sie selbst.
n8n als Low-Code-Plattform zeigte, dass auch mit einem monolithischen Single-Agent-System brauchbare Ergebnisse möglich sind – ideal für schnelle Prototypen und nicht-technische Nutzende, aber mit klaren Grenzen bei komplexen Multi-Agent-Szenarien.
6. Evaluation: Vier Ansätze, ein gemeinsames Problem
Bemerkenswert war, dass alle vier Teams eigenständig unterschiedliche Evaluationsstrategien entwickelten – ein Zeichen dafür, dass standardisierte Evaluationsmethoden für agentische Systeme noch fehlen.
Die Bandbreite reichte von Golden Datasets mit automatisierter Keyword-Prüfung über wissenschaftlich fundierte Entscheidungsbäume als Referenzstandard bis hin zur direkt in die Architektur integrierten Evaluation: Ein Judge-Node evaluiert jede Antwort, und ein Tool-Audit prüft, ob technische Behauptungen durch nachweisbare Tool-Aufrufe belegt sind. Kontrolliertes Testing mit identischem Input über mehrere Prototypen zeigte, dass diese konsistent zwei von drei identischen Frameworks empfahlen.
Die gemeinsame Erkenntnis: Offline-Tests allein reichen nicht. Erst der Live-Betrieb zeigt, ob ein Agent robust genug ist.
7. Lessons Learned
Über alle Teams hinweg ergeben sich Erkenntnisse, die auch für etablierte Entwicklungsteams relevant sind.
Evaluation muss live sein. Offline-Tests mit Golden Datasets sind essenziell für die Entwicklung. Aber nur Live-Guardrails schützen das System in der Produktion vor Reputationsschäden. Der Weg zur Antwort muss genauso gut sein wie die Antwort selbst.
Prompting ist Software Engineering. Die Inter-Agenten-Kommunikation beeinflusst die Ergebnisqualität ebenso stark wie die Nutzerkommunikation. JSON statt natürlicher Sprache, strukturierte Schemas, Persona-Prompting für klare Rollenverteilung: Das sind architekturrelevante Entscheidungen.
Einfach starten, iterativ erweitern. Mit einem simplen Single Agent beginnen und Komplexität nur dort hinzufügen, wo sie nachweislich bessere Ergebnisse liefert. Nicht jeder Use Case braucht ein Multi-Agent-System – aber wer eins braucht, sollte die Architektur-Optionen kennen.
MCP ist kein Selbstläufer. Die Anbindung externer Dokumentationen über MCP-Server klingt vielversprechend, lieferte in der Praxis aber nicht immer bessere Ergebnisse als gut kuratierte lokale Daten. Die Technologie ist noch jung.
Das Feld bewegt sich schnell. Alle Teams mussten während des Projekts Embedding-Modelle aktualisieren, API-Änderungen nachvollziehen und Framework-Updates integrieren. Wer agentische Systeme in Produktion bringen will, braucht einen Plan für kontinuierliche Aktualisierung.
8. Ausblick: Von Prompt Engineering zu Context Engineering
Eine treffende Analogie aus dem Projekt: Ältere Modelle wie GPT-4o-mini sind der „Azubi" – kostengünstig, aber fehleranfällig, und müssen mit detaillierten Anleitungen angeleitet werden. Aktuellere Modelle entsprechen eher einem „Meister": fachkompetent, reflektiert, weitgehend autonom.
Für die Architektur agentischer Systeme bedeutet das eine klare Verschiebung. Chain-of-Thought-Prompting und aufwändige Promptstruktur verlieren an Bedeutung – das übernehmen die Modelle zunehmend selbst. Wichtiger werden zwei Disziplinen: Context Engineering (dem Modell präzise, anwendungsfallspezifische Informationen bereitstellen) und Tool-Enablement (dem Modell die Fähigkeit geben, externe Werkzeuge umfassend zu nutzen).
Handlungsempfehlungen
-
Framework-Evaluation starten: Nicht abstrakt, sondern anhand von zwei bis drei konkreten Use Cases. Der Vergleich wird erst durch echte Implementierung aussagekräftig.
-
Context-Engineering-Kompetenz aufbauen: RAG-Pipelines, dynamische System-Prompts und strukturierte Inter-Agenten-Kommunikation sind die Basis für verlässliche Agenten-Outputs.
-
Evaluations-Pipeline definieren: Golden Datasets für Offline-Tests, LLM-as-a-Judge für automatisierte Qualitätsbewertung, Live-Guardrails für Produktionssysteme.
-
Ökosystem-Entscheidung treffen: Die Framework-Wahl hängt vom bestehenden Cloud-Ökosystem, von der Vendor-Lock-In-Toleranz und von den Kompetenzen im Team ab.
Fazit
Dieses Projekt hat gezeigt, dass die Frage „Welches Agentic-AI-Framework soll ich nehmen?" nur oberflächlich eine technische ist. Tatsächlich geht es um Architektur-Patterns, um die Qualität des Kontexts und um die Frage, wie ein Agentensystem in das bestehende IT-Ökosystem eines Unternehmens passt.
Vier Studierendenteams haben in kurzer Zeit zwölf Prototypen geliefert, die nicht nur funktionieren, sondern systematisch evaluiert und verglichen wurden – mit klaren Empfehlungen und Einordnung der Grenzen. Für Bosch, für die Lehre und für jeden, der agentische Systeme aufbauen will, sind die Ergebnisse direkt anschlussfähig.
Mein Dank geht an die Studierenden aller vier Teams für ihre hervorragende Arbeit. Ebenso an das Bosch-Team – Philipp Schneider, Sonja Buchholz, Alexandros Smponias, Lena Dorsch und Dr. Timurhan Sungur – für die engagierte Betreuung und die Bereitschaft, reale Praxis-Problemstellungen in die Lehre zu bringen.
FAQ
Welches Framework hat am besten abgeschnitten? Es gibt keinen klaren Gewinner über alle Dimensionen. Google ADK überzeugte im Google-Ökosystem, LangGraph bot die größte Flexibilität, OpenAI Agents SDK ermöglichte die schnellste Entwicklung, n8n war ideal für Low-Code-Prototypen. Die „beste" Wahl hängt vom konkreten Kontext ab.
Was war die überraschendste Erkenntnis? Zwei Dinge: Erstens hatte die Datenqualität im RAG-System einen größeren Einfluss als die Modellwahl. Zweitens lieferten MCP-Server für Framework-Dokumentationen nicht automatisch bessere Ergebnisse als gut kuratierte lokale Daten.
Lässt sich der Ansatz auf andere Unternehmen übertragen? Ja. Jedes Unternehmen, das mehrere KI-Tools oder Frameworks im Portfolio hat, steht vor derselben Herausforderung. Die Architektur-Patterns – Orchestrator, RAG mit internem Wissen, Judge-basierte Qualitätssicherung – sind framework-unabhängig und übertragbar.