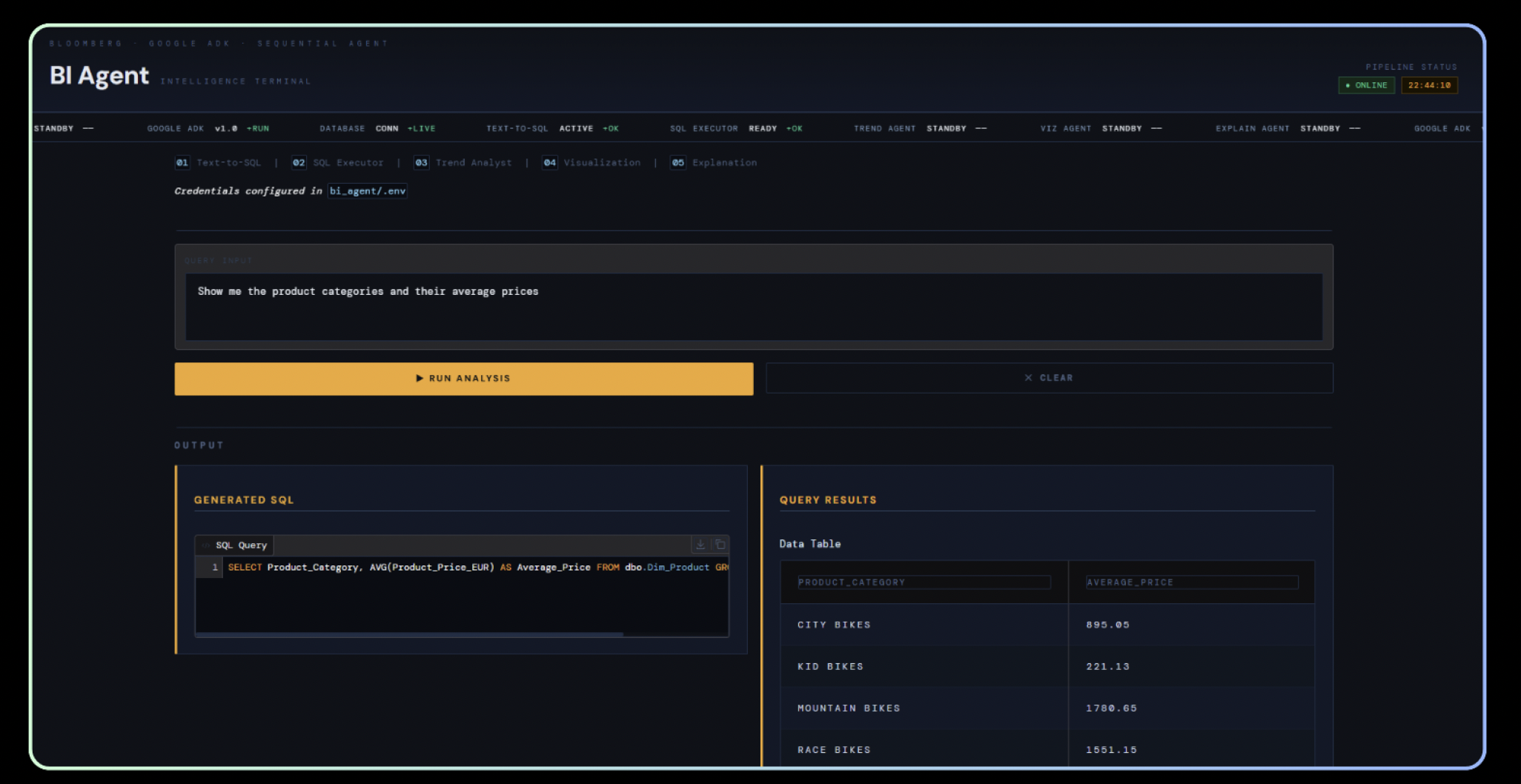
Auf einen Blick
- Mehrere Teams bauten denselben BI-Agenten, der Fachfragen in SQL übersetzt, ausführt, visualisiert und ergebnisse interpretiert.
- Zuverlässigkeit entstand aus SQL-Validierung, Limits und Retry-Loops, nicht aus längeren Prompts.
- Context Engineering war der größte Hebel, weil Schema-Preloading, semantische Layer und kuratierte Geschäftsregeln die Qualität stärker beeinflussten als Prompt-Länge.
- Hybride Architekturen mit deterministischem Python schlugen vollagentische Pipelines bei Latenz und Kontrolle.
- Transparenz in UI und Evaluation entschied über praktische Nutzbarkeit.
Self-Service Analytics mit Agentic AI soll natürliche Sprache in sicheres SQL übersetzen und das Ergebnis als Tabelle, Chart und Business-Einordnung liefern. Klingt einfach. Ist es nicht.
In einem Projekt mit dem King Mongkut's Institute of Technology Ladkrabang (KMITL) haben mehrere Teams im Agentic-AI-Modul des Management Information Systems Kurses denselben BI-Use-Case umgesetzt. Die Aufgabe war ein Python-basiertes System, das natürlichsprachliche Fragen gegen einen komplexen, mehrtabelligen SQL-Server-Datensatz übersetzt, ausführt und Tabelle, Chart und Interpretation liefert. Als technologische Basis dienten Python, Google ADK mit Gemini, Gradio, Microsoft SQL Server, GitHub und uv.
Die zentrale Frage war, welche Architekturentscheidungen den Unterschied machen, wenn ein System nicht nur als Demo funktionieren soll, sondern sicher, schnell und nachvollziehbar arbeiten muss.
1. Was sich über alle Teams hinweg gezeigt hat
Weil derselbe Use Case mehrfach unter ähnlichen Rahmenbedingungen umgesetzt wurde, sind die wiederkehrenden Muster interessanter als jede einzelne Lösung. Die stärkeren Implementierungen teilten eine Grundform aus kuratiertem Schema-Kontext, expliziter SQL-Validierung, deterministischem Code für nichtsprachliche Aufgaben, sichtbaren Queries in der Oberfläche und Evaluation jenseits von „die Demo lief einmal".
Eine einzig richtige BI-Agentenarchitektur gibt es nicht. Aber es gibt Entscheidungen, die Zuverlässigkeit, Latenz und Vertrauen konsistent verbessern.
2. Text-to-SQL: zuerst Systemproblem, dann Prompting-Problem
Text-to-SQL ist zuerst ein Systemproblem und erst danach ein Prompting-Problem.
Die stärkeren Teams behandelten SQL-Generierung als Modul in einer größeren Architektur mit expliziter Validierung, nur SELECT-artigen Queries, Blacklists für riskante Schlüsselwörter, Zeilenlimits und Timeouts, wobei die generierte Query stets in der Oberfläche sichtbar blieb.
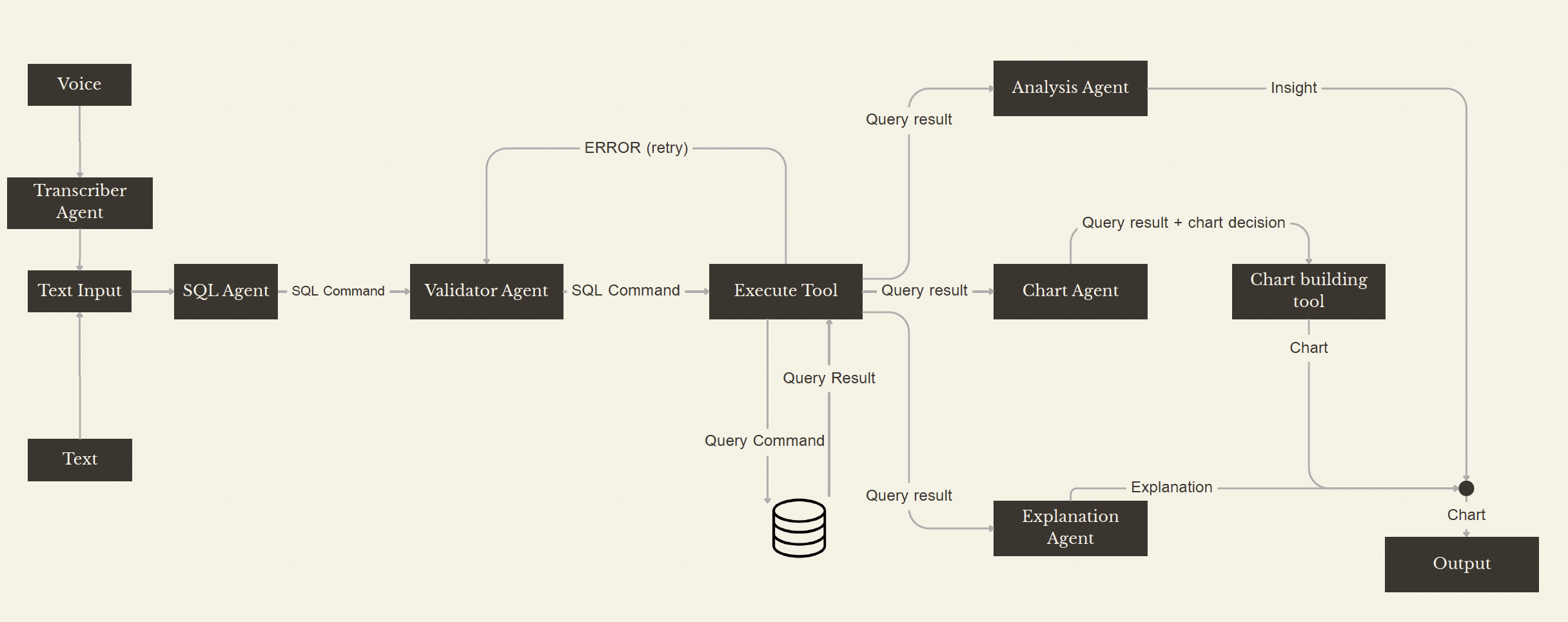
Eine Multi-Agent-Pipeline mit expliziter Validierung und Retry-Loop vor der eigentlichen Ausführung.
Die robustesten Systeme kombinierten weiche Leitplanken im Prompt mit harten Regeln im Code, darunter Row Caps, Query Timeouts, SELECT-only Enforcement und Validator-Schleifen, die Laufzeitfehler zurückspielen und die Query gezielt korrigieren. Ein BI-Agent, der elegant formuliert, aber unsicheres SQL ausführt, ist schlechter als gar kein Agent. Korrektheit entsteht nicht durch bessere Formulierung, sondern durch konsequente Begrenzung und Prüfbarkeit der Modellaktionen.
3. Context Engineering: Kontext schlägt Formulierung
Die besseren Implementierungen schrieben keine längeren Prompts, sondern verbesserten, wie das System das Datenmodell versteht.
Das bedeutet vorab geladene Schemainformationen, semantische Layer mit abgeleiteten Kennzahlen, explizite Chart-Taxonomien und reduzierte Mehrdeutigkeit, noch bevor überhaupt SQL generiert wird.
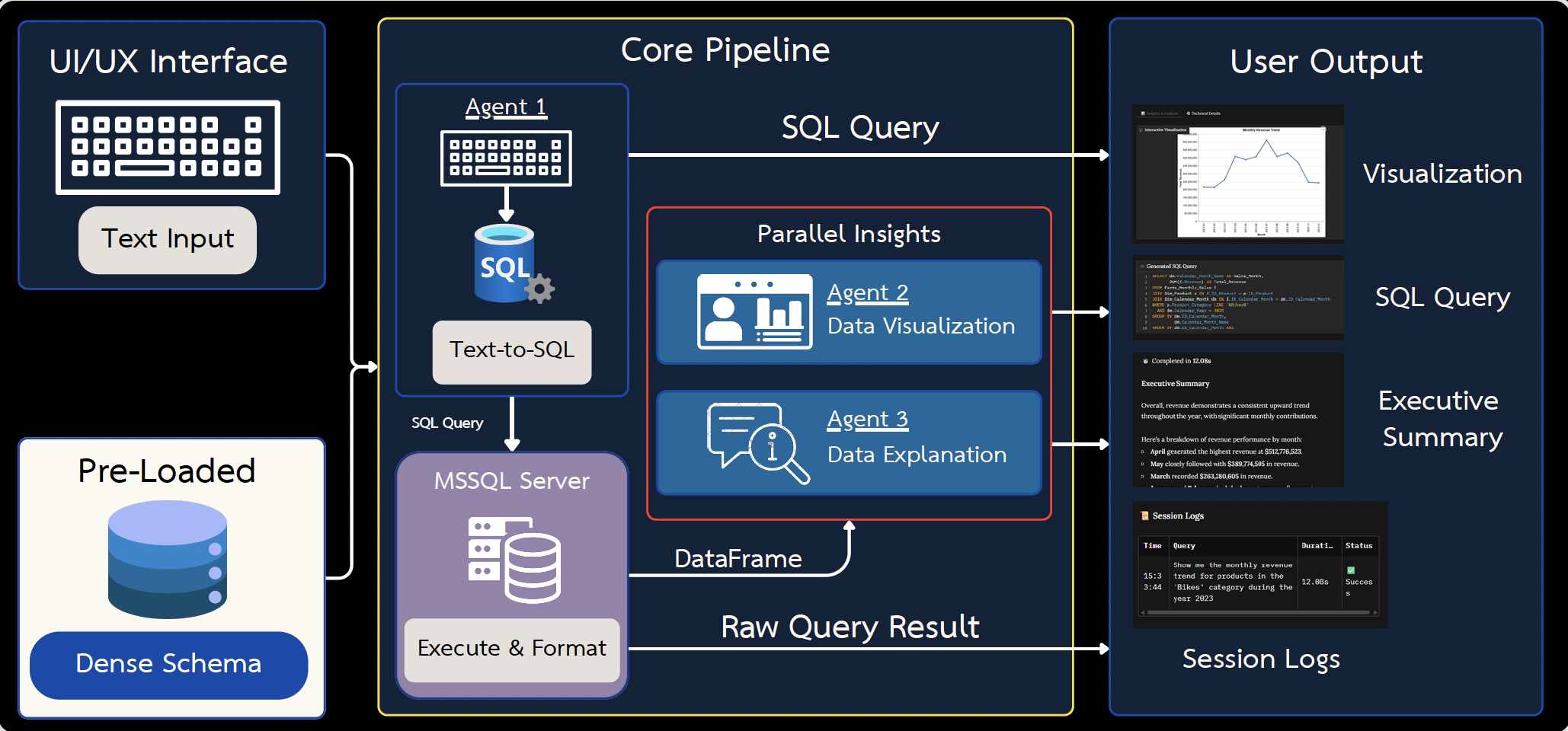
Ein optimierter Ablauf: Das Schema wird beim Start vorgeladen, Visualisierung und Erklärung laufen anschließend parallel.
Kennt ein Modell weder Tabellenbeziehungen noch Naming Conventions, Business-Metriken oder erlaubte Query-Muster, hilft ein längerer Prompt nicht. Den größten Hebel bildeten dichte Schema-Strings, annotierte Geschäftsregeln und dynamisch gefilterte Tabellenkontexte. In einer dokumentierten Variante sparte allein das Schema-Preloading rund 1.500 Tokens pro Anfrage.
4. Hybride Architektur: Weniger Agenten, bessere Ergebnisse
Die effektivsten Lösungen fügten nicht mehr Agenten hinzu, sondern entfernten welche, wo deterministischer Code schneller und kontrollierbarer war.
Schema-Caching, regelbasierte Weiterleitung, Python-basierte Nachbearbeitung und heuristische Fast Paths schlugen durchgehend vollagentische Ketten.
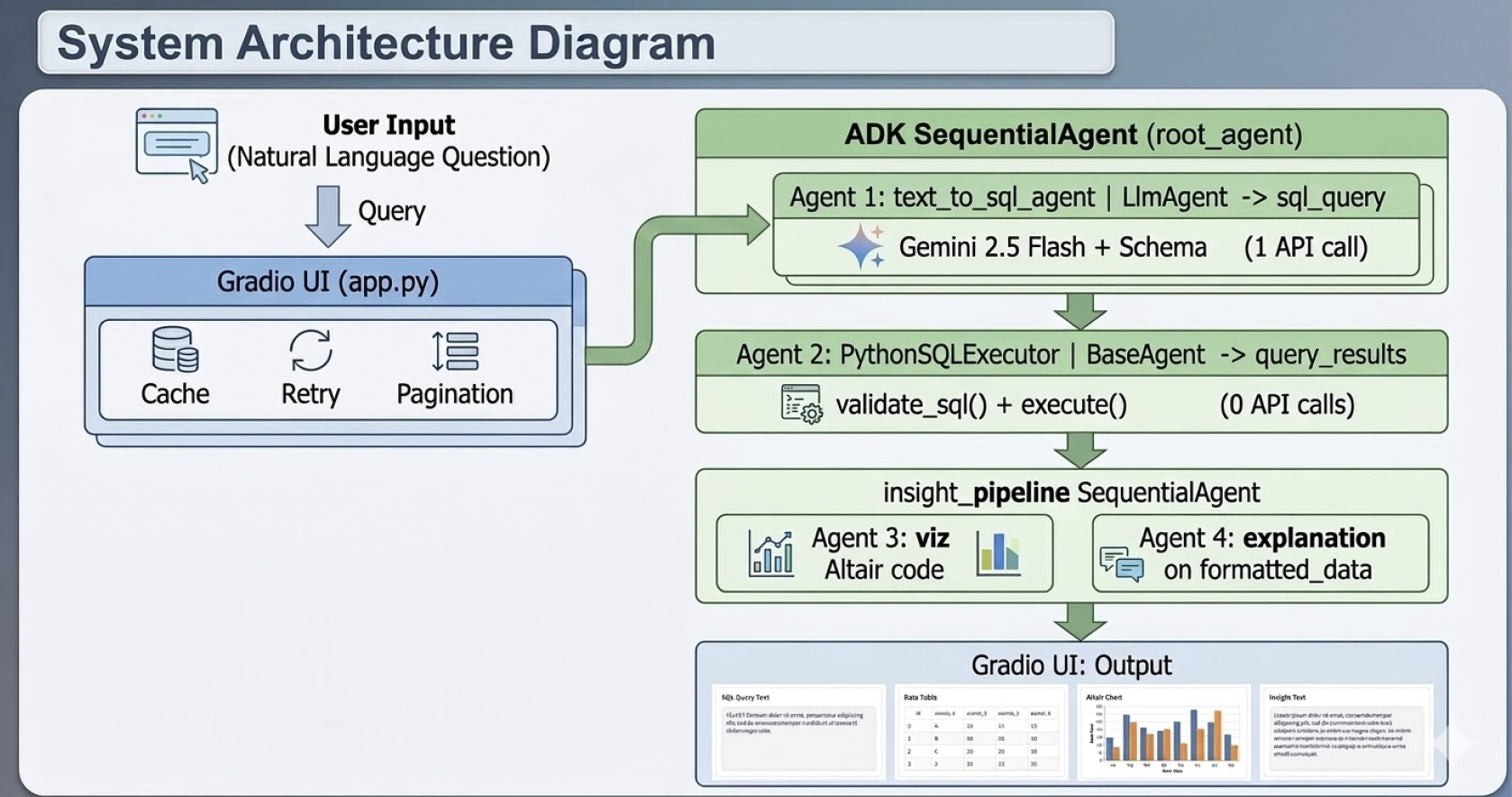
Eine sequentielle Architektur, in der SQL-Ausführung und Formatierung bewusst in deterministischem Python-Code bleiben.
In einer optimierten Variante sanken die LLM-Aufrufe von vier auf zwei, weil zwei Agentenschritte durch Python ersetzt wurden. In einer anderen fiel die Latenz von 32,4 auf 10,09 Sekunden durch Hybrid-Orchestrierung, Fast Paths und schlankere Prompts. Die relevante Frage ist nicht, wie viele Agenten man bauen kann, sondern welche Teile bewusst nicht vom Modell gesteuert werden sollten.
5. Transparenz: Nachvollziehbarkeit ist nicht verhandelbar
Wer einem BI-Agenten vertrauen soll, braucht Nachvollziehbarkeit und nicht nur eine finale Aussage.
Vertrauen entstand dort, wo Systeme die generierte Query zeigten, Rohdaten offenlegten, Export anboten, die Wahl der Visualisierung begründeten.
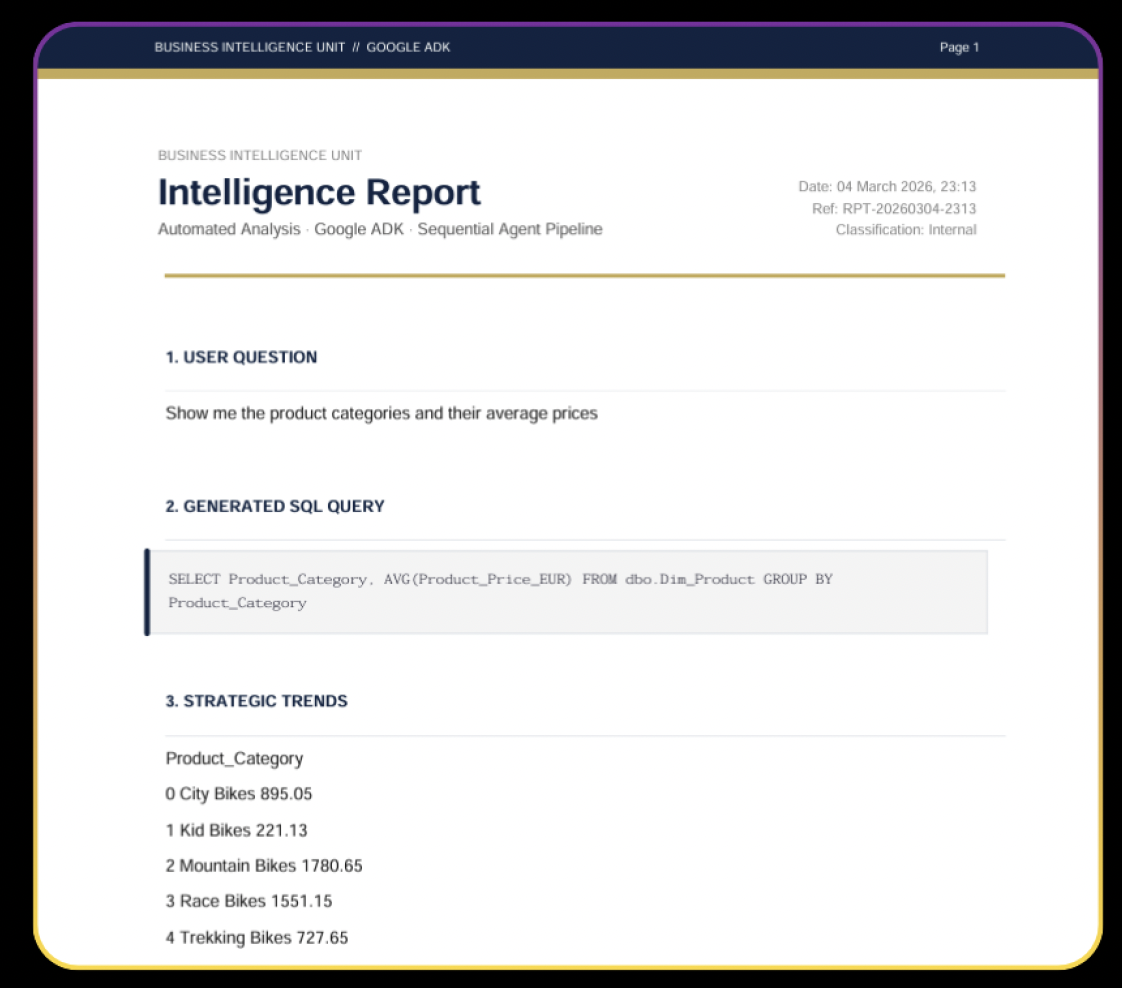
Ein exportfähiger Intelligence Report mit Frage, SQL, Ergebnis und geschäftlicher Einordnung.
Manche Teams optimierten für Management-Lesbarkeit, andere für technische Transparenz. Die gemeinsame Erkenntnis war, dass ein BI-Agent nur dann nützlich ist, wenn seine Ergebnisse verifizierbar und sein Vorgehen nachvollziehbar sind.
6. Evaluation: die schwierigste Aufgabe bleibt offen
Die reiferen Teams versuchten, ihre Systeme systematisch zu messen, indem sie Testfälle, Benchmark-Fragen, Referenz-SQL und explizite Prüfung der textlichen Erklärungen einsetzten.
Gerade die Unvollkommenheit war aufschlussreich. Ein Benchmark erreichte 75 % Execution Accuracy über 40 Fragen und dokumentierte Fehler durch Schema-Mehrdeutigkeit und Rundungsdifferenzen. In einem anderen Fall stieg ein teaminternes Ground-Truth-Benchmark von 2/10 auf 10/10 nach architektonischen Anpassungen. Judge-basierte Evaluation erleichterte strukturiertes Review, löste das Grundproblem aber nicht vollständig.
7. Handlungsempfehlungen
Agentic AI in Analytics ist vor allem ein Architekturthema. Nicht der Prompt macht den Unterschied, sondern die Entscheidung, was das Modell tut, was klassische Software übernimmt und wie das Ergebnis präsentiert wird.
- Schmaler End-to-End-Pfad zuerst. Verlässlich machen, bevor architektonisch ausgebaut wird.
- SQL-Ausführung hinter Validatoren, Limits und Timeouts. Keine Option, sondern Pflicht.
- In Schema-Kontext und Geschäftsregeln investieren, nicht in längere Prompts. Kontext schlägt Formulierung.
- Deterministische Schritte aus dem LLM-Loop herausziehen, sobald sie regelbasiert lösbar sind.
- SQL, Rohdaten, Logs und Fehlzustände in der Oberfläche zeigen. Debugging und Vertrauen von Tag eins mitbauen.
- Evaluation als Produktfeature behandeln mit Benchmark-Fragen, Ground-Truth-Queries und Live-Monitoring.
Fazit
Self-Service Analytics mit Agentic AI ist machbar, aber nicht als Demo-Thema. Sobald natürliche Sprache zu SQL, Visualisierung und Management-Erklärung werden soll, entscheidet die Systemarchitektur über Qualität und Sicherheit.
Beeindruckend war, wie schnell die Arbeit von der Faszination über „AI Agents" in echtes Engineering überging, also in Validierung, Architektur, Trade-offs, Observability und Nutzervertrauen. Selbst im Lehrkontext entstanden Prototypen nah an realen Analytics-Produkten. Der Unterschied zwischen eindrucksvoller Demo und belastbarem System liegt nicht im Prompt, sondern in der Architektur dahinter.
Mein Dank gilt den Studierendenteams für die beeindruckenden Prototypen sowie Asst. Prof. Kanokwan Atchariyachanvanich und KMITL für die Zusammenarbeit.