Lokale LLMs in der Industrie: Warum Text-to-SQL mehr als ein Modellproblem ist
Viele Unternehmen würden generative KI gern näher an ihre produktiven Prozesse bringen, etwa in Form von Text-to-SQL-Systemen, die natürlichsprachliche Fragen direkt in Datenbankabfragen übersetzen. Gerade dort stoßen sie aber schnell an eine grundlegende Grenze: Cloud-Modelle sind aus Datenschutz-, Sicherheits- oder Infrastrukturgründen nicht immer ein realistischer Weg. Damit verschiebt sich der Fokus. Die entscheidende Frage lautet dann nicht mehr nur, welches Modell lokal betrieben werden kann. Wichtiger ist, ob ein System unter realen Bedingungen robust genug ist, natürlichsprachliche Anfragen in verlässliche Datenbankabfragen und belastbare Antworten zu übersetzen.
Genau an dieser Stelle setzt die Masterarbeit von Aaron Stark an, die ich gemeinsam mit Dr. Jannis Hanke von der Dürr Systems AG (DXQ Analytics and AI) betreut habe. Untersucht wurde, wie lokale Large Language Models für die Analyse strukturierter Prozessdaten eingesetzt werden können. Im Zentrum stand ein anspruchsvoller Text-to-SQL-Anwendungsfall: Statistik- und Alarmdaten aus industriellen Lackieranlagen sollten per natürlicher Sprache analysierbar werden. Dafür wurde ein Prototyp entwickelt und systematisch evaluiert.
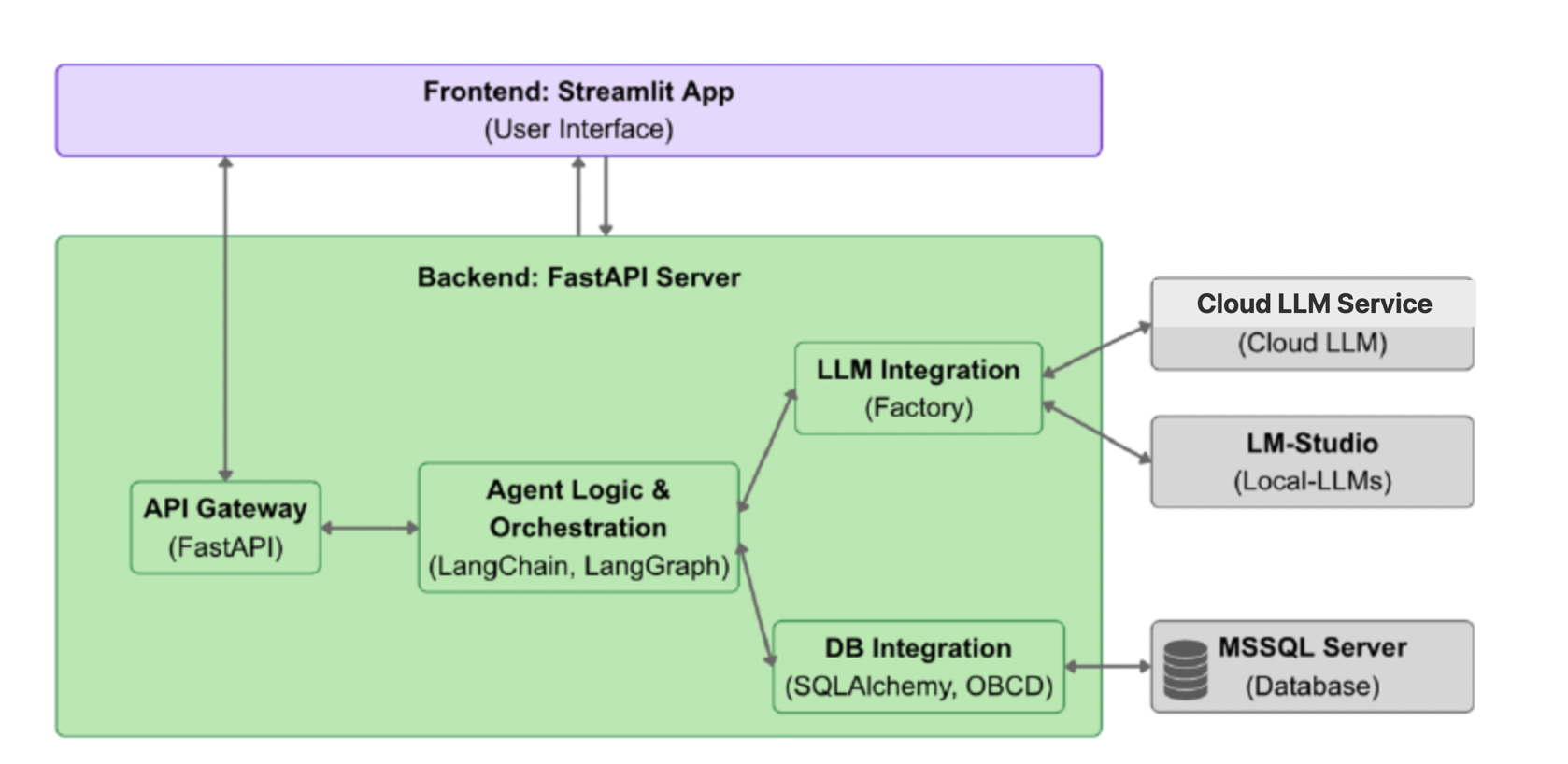
Abbildung: Systemarchitektur des Prototyps zur natürlichsprachlichen Analyse industrieller Prozessdaten.
Der Erkenntniswert dieser Arbeit liegt dabei nicht nur in der Frage, welches lokale Modell besser oder schlechter abgeschnitten hat. Interessanter ist die übergeordnete Einsicht: In industriellen Umgebungen ist Text-to-SQL weniger ein reiner Modelltest als ein Systemtest. Architektur, Kontext, Domänenwissen und Datenstruktur greifen hier enger ineinander, als es viele GenAI-Debatten nahelegen.
Warum Text-to-SQL in der Industrie ein anderer Use Case ist
Text-to-SQL wirkt auf den ersten Blick wie ein naheliegender GenAI-Anwendungsfall. Eine Nutzerin formuliert eine Frage in natürlicher Sprache, das System erzeugt ein SQL-Statement, führt es aus und liefert eine Antwort zurück. In Demo-Szenarien mit kleinen, gut beschriebenen Datenmodellen funktioniert das oft erstaunlich gut. Genau hier liegt aber auch die methodische Falle: Arbeiten zu Text-to-SQL auf realen Unternehmensdatenbanken zeigen seit einiger Zeit recht klar, dass produktive Datenlandschaften andere Probleme erzeugen als Benchmark-Schemata (Nascimento et al., 2025; Sun et al., 2023).
Im industriellen Umfeld verändert sich das Bild jedoch deutlich. Dort treffen Sprachmodelle nicht auf ein didaktisch sauberes Beispielschema, sondern auf verteilte Datenquellen, operative Datenbanken, fachliche Sonderlogiken und historisch gewachsene Strukturen. Genau daraus entsteht die eigentliche Komplexität. Forschung zu Schema Linking und zur Zerlegung komplexer Anfragen weist in dieselbe Richtung: Je realer und heterogener die Datenbasis, desto stärker entscheidet die Vorverarbeitung über die Ausführungsqualität (Wang et al., 2025; Pradeep et al., 2025).
Im vorliegenden Fall waren insbesondere fünf Faktoren relevant:
- Die Daten lagen nicht in einer einzigen konsolidierten Datenbank vor, sondern verteilt über mehrere Quellen.
- Unterschiedliche Datenbanktypen mussten gemeinsam interpretiert werden, etwa Statistik- und Alarmdaten.
- Die zugrunde liegenden Schemata waren auf operative Speicherung, nicht auf LLM-Lesbarkeit optimiert.
- Fachbegriffe, Stationsbezeichnungen und Zeitlogiken mussten korrekt auf technische Strukturen gemappt werden.
- Viele Nutzerfragen erforderten nicht nur SQL-Generierung, sondern auch Aggregation, Berechnung und domänenspezifische Interpretation.
Gerade in diesem Zusammenspiel zeigt sich, dass die Leistungsfähigkeit eines Systems nicht allein vom Modell abhängt. Sie entsteht erst durch das Verhältnis von Datenstruktur, Kontext, Tooling und Systemarchitektur.
Was in der Arbeit untersucht wurde
Erstellt wurde ein Prototyp, der natürlichsprachliche Anfragen an strukturierte industrielle SQL-Daten verarbeitet. Besonders aufschlussreich ist dabei die Entwicklung über zwei Iterationen hinweg. In einer ersten Fassung wurde ein vergleichsweise schlankes Multi-Agent-Setup aufgebaut. In einer zweiten Iteration wurde die Architektur gezielt erweitert, um erkannte Schwächen zu adressieren. Hinzu kamen unter anderem ein dedizierter Calculator-Agent für deterministische Berechnungen und ein Synthesizer-Agent für die strukturierte Aufbereitung der Ergebnisse. Dass eine solche explizite Arbeitsteilung gegenüber monolithischen Ansätzen Vorteile haben kann, zeigen auch neuere Arbeiten zu Multi-Agent-Architekturen für Text-to-SQL (Heidari et al., 2025).
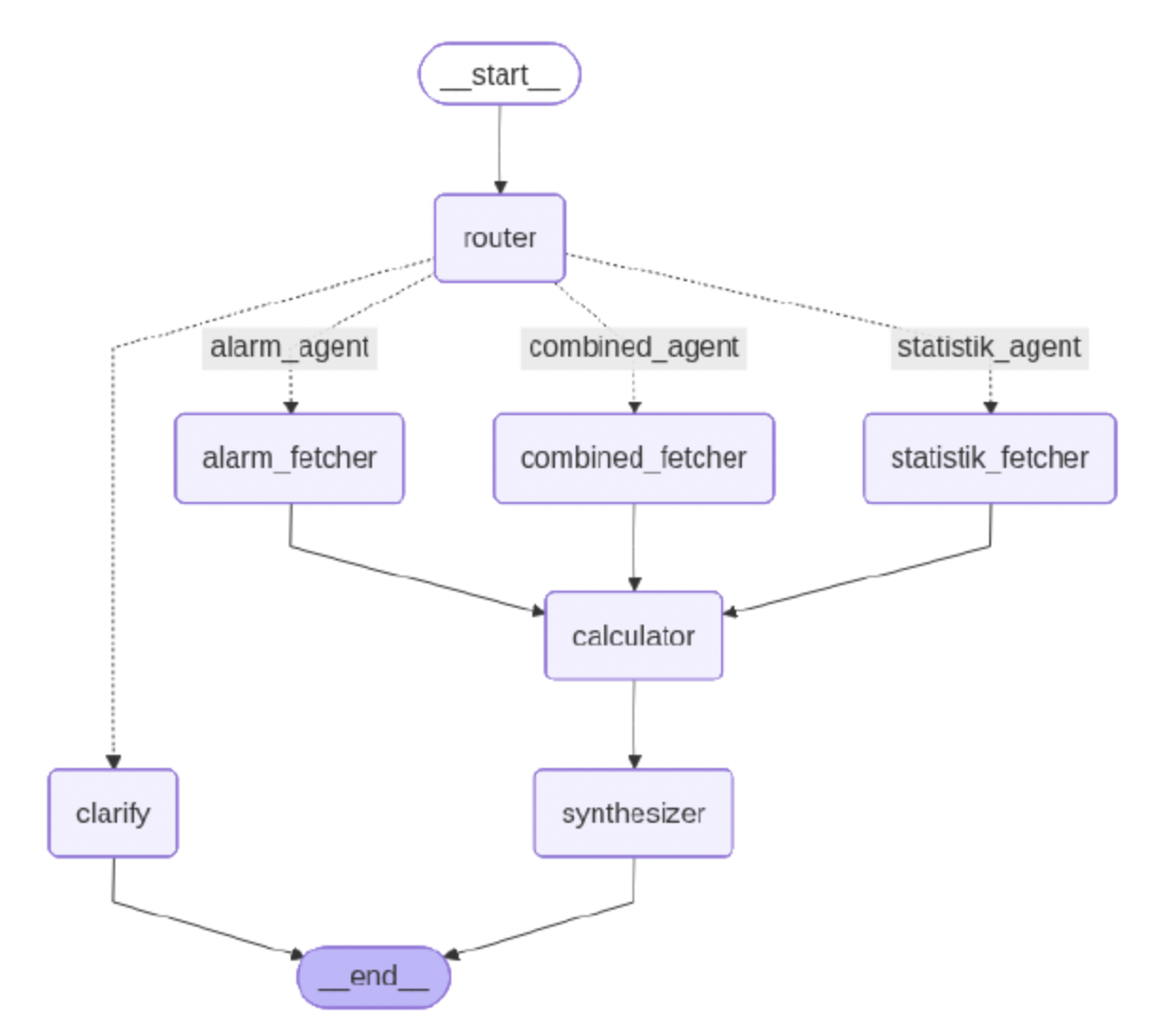
Abbildung: Multi-Agent-Architektur mit Routing, Datenbeschaffung, Berechnung und Antwortsynthese.
Genau diese Entwicklung macht den Erkenntniswert der Arbeit aus. Sie zeigt, dass sich produktionsnahe GenAI-Systeme nicht primär durch größere oder vermeintlich stärkere Modelle verbessern, sondern durch eine präzisere Architektur, klar getrennte Verantwortlichkeiten und das gezielte Zusammenspiel von Modell, Tools und Datenlogik.
Die eigentliche Erkenntnis: Nicht das Modell allein entscheidet
Eine der wichtigsten Einsichten der Arbeit ist, dass lokale LLMs nicht einfach dann brauchbar werden, wenn man ein ausreichend großes Modell lokal betreibt. Der eigentliche Engpass liegt häufig an anderer Stelle: in der Systemarchitektur.
In der ersten Iteration zeigte sich, dass einzelne Agenten zu viele Aufgaben gleichzeitig übernehmen mussten. Sie sollten Anfragen verstehen, Datenquellen unterscheiden, SQL erzeugen, Zwischenergebnisse aggregieren und die finale Antwort formulieren. Gerade lokale Modelle reagieren auf eine solche Überladung empfindlich. Kontextfenster werden ineffizient genutzt, Tool-Aufrufe werden unzuverlässig und numerische Fehler häufen sich.
Erst die klarere Trennung in Routing, Datenbeschaffung, Berechnung und Antwortsynthese stabilisierte das System sichtbar. Besonders aufschlussreich ist dabei, dass die zweite Iteration vor allem zuvor schwache Modelle deutlich verbesserte, während die Architektur mehr Einfluss auf die Ergebnisqualität hatte als Modellgröße oder Quantisierung der lokalen Modelle. Das ist mehr als ein technisches Detail. Es ist eine strategische Einsicht für Unternehmen: Wer lokale KI in operativen Kontexten einsetzen will, sollte nicht mit der Modellfrage beginnen, sondern mit der Frage nach Systemarchitektur und Workflow-Design.
Warum Context Engineering zum entscheidenden Hebel wird
Die Arbeit bestätigt zugleich eine Beobachtung, die sich derzeit in vielen GenAI-Projekten zeigt: Gute Ergebnisse entstehen nicht primär durch einen besonders gut formulierten Einzelprompt. Entscheidend ist, wie präzise der fachliche und technische Kontext aufbereitet wird. Dass Context Engineering als eigene Disziplin inzwischen stärker in den Vordergrund rückt, wird auch in der neueren Literatur deutlich (Mei et al., 2025; Hua et al., 2025).
Damit lokale Modelle in diesem Anwendungsfall überhaupt belastbare SQL-Statements erzeugen konnten, mussten mehrere Dinge zusammenkommen: klare Rollenbeschreibungen für Agenten, Few-Shot-Beispiele, domänenspezifische Mappings für Fachbegriffe, explizite Constraints und ein sauberes Schema-Linking zwischen Nutzerfrage und Datenbankstruktur.
Das klingt zunächst nach Prompt Engineering. Tatsächlich geht es um mehr. Das Modell muss nicht nur Sprache verstehen, sondern eine Brücke zwischen Fachlogik und Datenbankschema schlagen. Wenn diese Brücke nicht explizit gebaut wird, scheitert das System nicht an fehlender Sprachkompetenz, sondern an fehlendem Kontext.
Gerade im Industrieumfeld ist das relevant. Ein Begriff, der für Fachanwender eindeutig erscheint, ist für das Modell ohne Mapping oft nicht anschlussfähig. Hinzu kommt ein Punkt, den die Arbeit sehr klar macht: Diese Mappings und Beispiele entstehen nicht im luftleeren Raum, sondern im engen Austausch mit Fachbereichsexperten. Context Engineering ist hier deshalb kein nachgelagerter Optimierungsschritt, sondern ein Kernbestandteil des Systemdesigns.
Deterministische Komponenten sind keine Kür
Sobald Nutzerfragen Berechnungen, Summen, Mittelwerte oder datenbankübergreifende Aggregationen enthalten, geraten Sprachmodelle schnell in einen Bereich, in dem sprachliche Plausibilität und mathematische Korrektheit auseinanderlaufen. Genau hier liegt eine der praktischen Grenzen vieler GenAI-Systeme.
Die Arbeit reagiert darauf mit einer architektonisch sauberen Entscheidung: Rechenlogik wird nicht dem Modell überlassen, sondern in einen dedizierten Calculator-Agent ausgelagert, der deterministische Werkzeuge nutzt. Das reduziert Interpretationsspielraum und erhöht die Verlässlichkeit der Ergebnisse.
Diese Entscheidung ist grundlegend. Sprachmodelle sind stark darin, Anfragen zu verstehen, Informationen zu strukturieren und Antworten zu formulieren. Sie sind deutlich weniger verlässlich, wenn Berechnungen, mehrstufige Aggregationen oder fachkritische Transformationen im Modell selbst stattfinden sollen. Für produktive Systeme folgt daraus der klare Grundsatz, dass relevante Faktenverarbeitung dort, wo möglich, deterministisch umgesetzt werden sollte.
Noch konsequenter wäre es, Berechnungen direkt auf Datenbankebene durchzuführen, sofern die Datenstruktur dies zulässt. Auch diese Richtung wird in der Arbeit als sinnvolle Weiterentwicklung sichtbar.
Was die Evaluation über lokale Modelle zeigt
Die Evaluation basiert auf einem Golden Dataset mit 33 Testszenarien unterschiedlicher Komplexität sowie auf dem Vergleich mehrerer lokaler Modelle mit einer Cloud-Referenz.
Erfreulich ist, dass lokale Modelle in diesem Anwendungsfall grundsätzlich sinnvoll einsetzbar sind. Sie können natürlichsprachliche Anfragen in SQL überführen und in einem wohldefinierten Setup verwertbare Ergebnisse liefern. Damit ist die zentrale Grundannahme der Arbeit bestätigt: Lokale LLMs sind für industrielle Analyseumgebungen nicht per se ungeeignet.
Gleichzeitig zeigt die Evaluation, dass die gewählte Implementierung noch nicht die Antwortqualität erreicht, die für einen produktiven Einsatz erforderlich wäre. Das lässt sich jedoch nicht allein auf die Verwendung lokaler Modelle zurückführen. Gerade bei komplexen, kombinierten oder numerisch anspruchsvollen Fragestellungen zeigten sich Schwächen im Zusammenspiel aus Architektur, Tool-Nutzung, Kontextaufbereitung und Datenstruktur. Ebenso interessant ist, dass sich kein einfacher Zusammenhang nach dem Muster "größeres Modell gleich besseres Ergebnis" bestätigen ließ. Auch die Quantisierung der lokalen Modelle erklärte die Unterschiede nicht hinreichend.
Für die Praxis ist genau das wichtig. Die Modellgröße allein ist kein belastbarer Kompass. Entscheidend ist, wie gut ein Modell unter den gegebenen Infrastrukturbedingungen, innerhalb der gewählten Agentenlogik und mit dem verfügbaren Kontext tatsächlich arbeitet. Für die betrachtete Infrastruktur erwiesen sich Modelle unterhalb von 40 Milliarden Parametern dabei als pragmatisch sinnvoll, weil sie noch in ein realistisches Verhältnis von Qualität, Antwortzeit und verfügbarer Hardware passen.
Die unterschätzte Dimension: Datenbankdesign
Eine besonders wertvolle Einsicht der Arbeit liegt jenseits des eigentlichen Modellvergleichs. Sie betrifft die Struktur der zugrunde liegenden Datenbanken.
Wenn Daten stark verteilt, hochgradig normalisiert und nicht auf lesende Analysezugriffe ausgelegt sind, erhöht das die Komplexität des gesamten Systems erheblich. Prompts werden länger, Tool-Landschaften komplexer, Kontextfenster knapper und Fehlerrisiken größer. Was dann oft wie ein Modellproblem aussieht, ist in Wahrheit ein Strukturproblem.
Die Handlungsempfehlung der Arbeit ist deshalb überzeugend: Daten für ein solches Agenten-System sollten möglichst in eine lesefreundliche, zentralisierte und für LLMs interpretierbare Struktur überführt werden. Anders formuliert: Wer Text-to-SQL im Unternehmen ernsthaft einsetzen will, muss nicht nur über Modelle und Frameworks sprechen, sondern auch über Datenmodellierung, ETL-Prozesse und analytische Zielstrukturen.
Gerade hier zeigt sich, dass KI-Strategie und Datenarchitektur enger zusammenhängen, als es in vielen Diskussionen den Anschein hat.
Was Unternehmen daraus ableiten können
Die Arbeit macht einen Reifegradunterschied sichtbar, der in vielen GenAI-Initiativen zu beobachten ist. Auf der ersten Stufe steht die Frage: Welches Modell sollen wir verwenden? Auf der nächsten, deutlich relevanteren Stufe, verschiebt sich der Fokus:
- Welche Architektur braucht dieser Use Case tatsächlich?
- Welche Aufgaben dürfen dem Modell überlassen werden und welche nicht?
- Wie muss der Kontext gestaltet werden, damit das Modell fachlich korrekt arbeitet?
- Welche Datenstrukturen erschweren das System unnötig?
- Wie wird Qualität systematisch evaluiert, statt nur subjektiv eingeschätzt?
Gerade im industriellen Umfeld reicht es nicht, ein LLM an Datenbanken anzuschließen und auf brauchbare Antworten zu hoffen. Notwendig sind ein belastbares Systemdesign, Domänenwissen aus dem Fachbereich und eine saubere Evaluationslogik. Dass die Arbeit hier mit einem Golden Dataset und einer systematischen Bewertung der Antworten und Routen arbeitet, ist deshalb kein Nebenaspekt, sondern Teil ihrer eigentlichen Aussagekraft. Methodisch greift die Arbeit dabei auf das LLM-as-a-Judge-Verfahren zurück, das derzeit eine hohe Resonanz erfährt (Li et al., 2024).
Handlungsempfehlungen
Aus den Ergebnissen lassen sich mehrere übertragbare Empfehlungen ableiten:
- Architektur vor Modellwahl priorisieren. Die Frage nach Agentenlogik, Tool-Nutzung, Routing und Fehlertoleranz ist häufig wichtiger als die Wahl des neuesten Modells.
- Deterministische Schritte konsequent auslagern. Berechnungen, Aggregationen und fachkritische Verarbeitung sollten möglichst nicht dem Modell allein überlassen werden.
- Context Engineering systematisch aufbauen. Fachbegriffe, Datenbanklogik, Few-Shot-Beispiele und Schema-Mappings sind keine kosmetischen Ergänzungen, sondern zentrale Produktbestandteile.
- Datenlandschaft für Analysezugriffe vorbereiten. Verteilte operative Datenbanken sind selten ein guter Zielzustand für robuste Text-to-SQL-Systeme.
- Mit realistischen Testszenarien evaluieren. Ein Golden Dataset mit klaren Referenzantworten ist für produktionsnahe KI-Systeme keine Kür, sondern Grundvoraussetzung.
Fazit
Die Masterarbeit von Aaron Stark zeigt deutlich, worin die eigentliche Herausforderung beim Einsatz lokaler LLMs im industriellen Umfeld liegt. Nicht das lokale Modell allein entscheidet über den Erfolg, sondern das Zusammenspiel aus Architektur, Kontext, Datenstruktur, Expertenwissen und deterministischen Komponenten.
Gerade deshalb ist die Arbeit über den konkreten Anwendungsfall hinaus relevant. Sie liefert keine einfache Erfolgsgeschichte nach dem Muster, dass lokale KI die Cloud ersetzt. Sie liefert etwas Nützlicheres: einen realistischen Blick darauf, unter welchen Bedingungen lokale LLMs in sensiblen industriellen Umgebungen sinnvoll einsetzbar sind, und wo ihre Grenzen derzeit noch verlaufen.
Quelle
- Aaron Stark (2026). Entwurf und Evaluation eines Prototyps zur Analyse industrieller Prozessdaten unter Einsatz lokaler Large Language Models. Unveröffentlichte Masterarbeit, Hochschule der Medien Stuttgart, in Kooperation mit Dürr.
Weiterführende Quellen
- Nascimento et al. (2025). LLM-Based Text-to-SQL for Real-World Databases
- Wang et al. (2025). LinkAlign: Scalable Schema Linking for Real-World Large-Scale Multi-Database Text-to-SQL
- Pradeep et al. (2025). Divide, Link, and Conquer: Recall-oriented Schema Linking for NL-to-SQL via Question Decomposition
- Heidari et al. (2025). AGENTIQL: An Agent-Inspired Multi-Expert Framework for Text-to-SQL Generation
- Mei et al. (2025). A Survey of Context Engineering for Large Language Models